Structured Inputs
The model receives a text prompt, target ego motion, and a semi-dense 3D environmental memory with ego-exo pose controls, separating static scene structure from human dynamics.
Egocentric Video Generation
Meta Reality Labs · University of Toronto
Abstract
Controllable and physically grounded egocentric video generation is essential for embodied agents to reason about how their own and others' actions manifest and change the world. Compared to generic video synthesis, egocentric generation is especially challenging: the camera is tightly coupled to the actor, leading to rapid viewpoint changes and frequent self-occlusions; the underlying actions are subtle, articulated, and often only partially visible; and both the people and the scene state must evolve consistently with the specified controls. We present E3C, a controllable video diffusion framework for egocentric generation that builds structured and compact conditions disentangling persistent scene structure from human-driven dynamics. From context frames, E3C constructs a semi-dense point cloud-based 3D memory and augments each point with appearance descriptors from video-VAE features. Rendering this memory into target viewpoints produces conditioning aligned with the target frames. Human dynamics are modeled separately. The observed people in the scene are controlled by skeleton renderings (exo human control), while the camera wearer is specified by their 3D body joints and 6DoF wrist motion (ego human control). To preserve ego human control when the wearer's body parts are invisible, we introduce an ego motion encoder that produces persistent cross-attendable tokens. Experiments on Nymeria show that E3C improves visual fidelity, camera-motion accuracy, object consistency, and ego & exo human control over strong baselines, while also enabling intuitive scene editing.
Rendered point-cloud memory keeps the world anchored across rapid head motion.
3D body and wrist trajectories steer first-person hands and body motion.
Rendered skeletons guide people observed in the egocentric scene.
Objects, people, camera paths, and action-scene composition can be changed explicitly.
Method
E3C turns text, 3D environmental memory, and ego-exo motion controls into aligned conditioning streams for a latent video diffusion transformer.
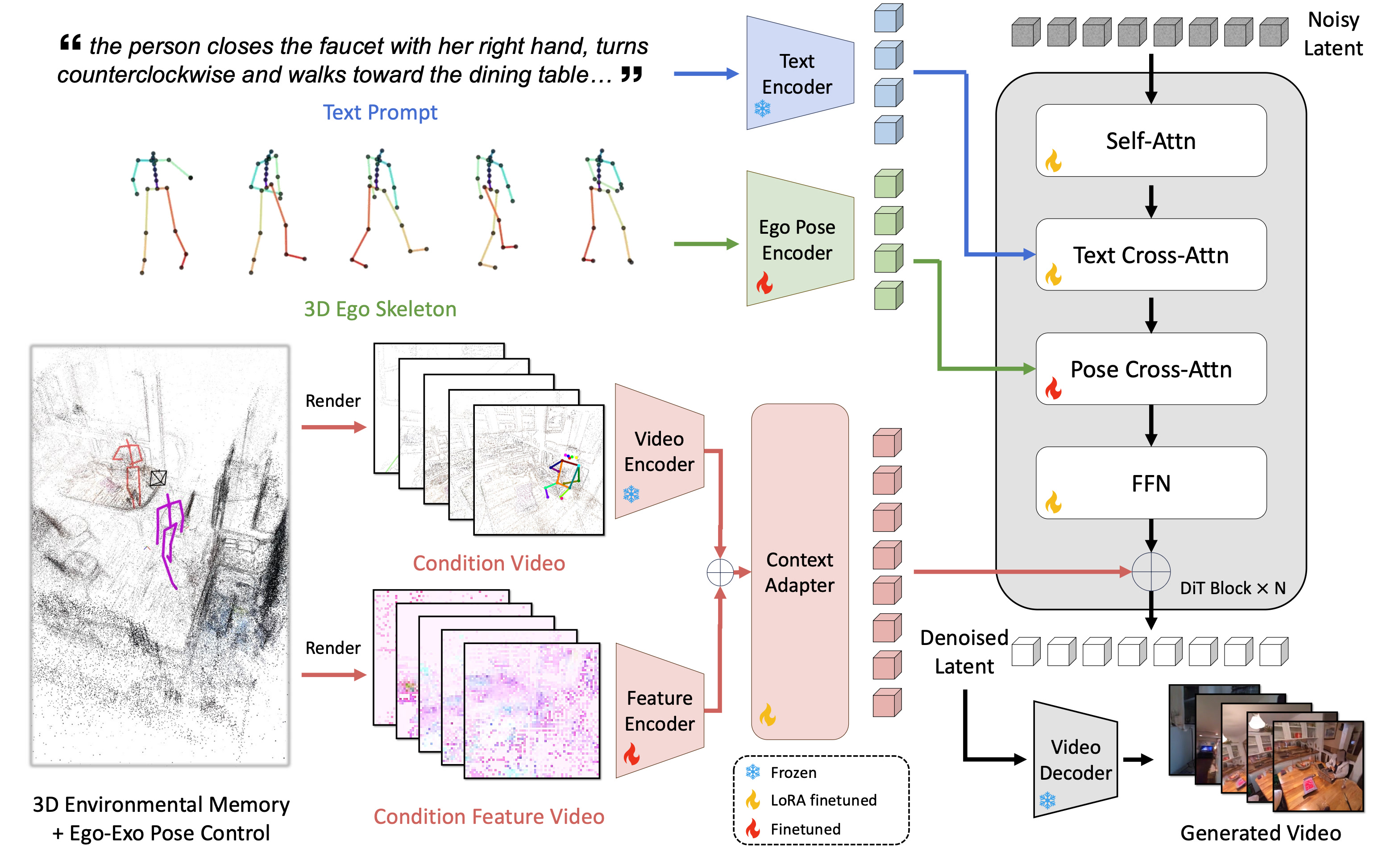
The model receives a text prompt, target ego motion, and a semi-dense 3D environmental memory with ego-exo pose controls, separating static scene structure from human dynamics.
The 3D memory and pose controls are rendered into the target camera viewpoints as a condition video and a condition feature video, aligning control signals with each frame.
Text, rendered controls, and ego pose tokens enter the diffusion backbone through cross-attention and adapter pathways, guiding generation while preserving the pretrained prior.
Qualitative Results
Qualitative Comparisons
Uses appearance-augmented memory and ego-exo pose control together.
Ground-truth target video from the same controls.
Struggles to use semi-dense point-cloud conditioning directly.
Recovers motion but misses color and texture details.
Accurate where reconstructed, with artifacts outside the context views.
Sharp egocentric view changes can produce ghosting artifacts.
Chunked generation can introduce jumps between camera views.
Ablations
Per-point appearance features help preserve color information and texture details.
Exo pose control helps the generated person follow the intended motion.
Ego human pose control enables precise body motion aligned with the target action.
Scene Editing
In this example, the chairs and the hanging lamp are consistently removed.
In this example, the coach is removed by editing the 3D memory.
In this example, the exo person is removed from the generation.
By combining the ego human poses from one video and spatial memory from another, we can compose video generation with any actions and any scene.
Citation
@article{gu2026e3c,
title={E3C: Video Generation with 3D Environmental Memory and Ego-Exo Human Pose Control},
author={Gu, Qiao and Ma, Lingni and Harley, Adam W and Newcombe, Richard and Shkurti, Florian and Straub, Julian},
journal={arXiv preprint arXiv:2605.26316},
year={2026}
}